
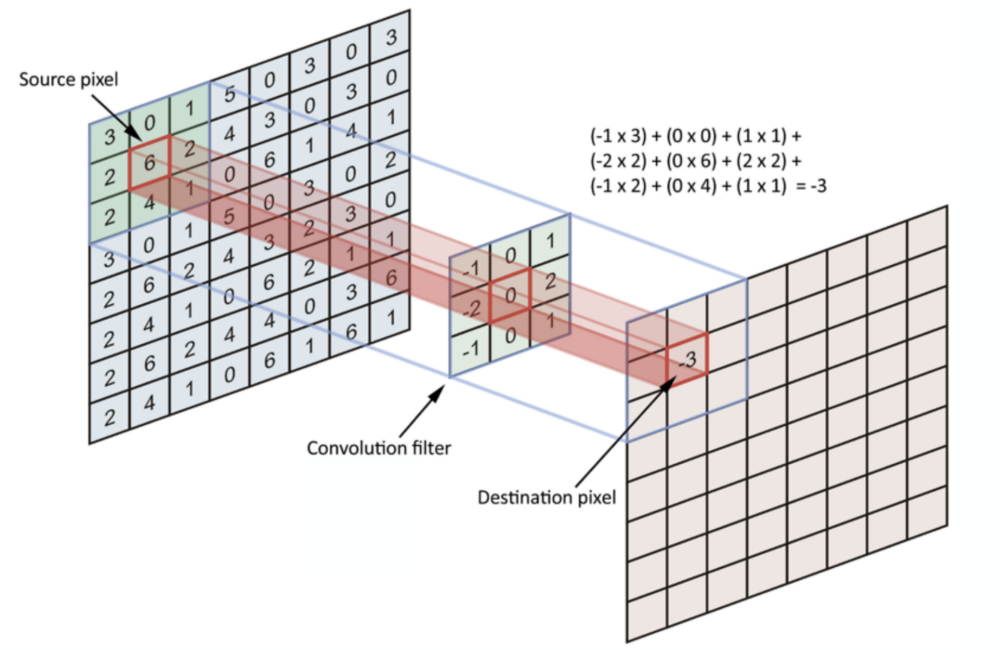
In the last post we went through all the building blocks of ConVNets. Now let’s put all the concepts together and see how to do it in Pytorch. Before going into the implementation , lets see what is Data Augmentation.
Augmentation:
Using pytorch’s torchvision.transforms operations , we can do data augmentation.With data augmentation we can flip/shift/crop images to feed different forms of single image to the Network to learn. Your training set may have certain images of particular form , example – in cat images , cat may appear centrally in the image .
However in unseen test data set cat may appear in left / right side of the images. Using data augmentation we can solve this problem by training out model with different forms of a single image.
The transforms operations are applied to your original images at every batch generation. So your dataset is left unchanged, only the batch images are copied and transformed in every iteration.

Let’s lets put everything together and build a ConvNet image classifier from scratch.
Press up/down/right/left arrow to browse the below notebook.
Do like , share and comment if you have any questions.