
With the hype of ChatGPT/LLMs I thought about writing a blog post series on the LLMs. This series would be more on Finetuning LLMs and how we can leverage LLMs to perform NLP tasks. We will start with discussing different types of LLMs, then slowly we will move to fine-tuning of LLMs for specific downstream tasks and how we can do different tasks using python/pytorch (Tutorial series: Deep Learning with Pytorch (aritrasen.com) ).
Large Language Models (LLMs) are foundational machine learning models that use deep learning algorithms to process and understand natural language. These models are trained on massive amounts of text data to learn patterns and contextual relationships in the given language. LLMs can perform different types of language tasks, such as translation of languages, sentiments prediction, act as chatbot, text summarization and more. They have the capability to generate text according to the context and texts which are grammatically and syntactically correct. These models are very large to into a general computer and mainly models are stored in different model hubs like HuggingFace. In this blog post series, I assume you know the concepts of Transformers / Self Attention / and basic hands working of HuggingFace models.
In case you want a fresher on the workings of HuggingFace models, below are some of my previous posts that can help.
Broadly we can classify LLMs into three categories:
- Encoder-only Models:
These models are bidirectional in nature and mainly for downstream tasks like – Sentiment Analysis, Classification task, Named Entity recognition. Models are trained using mainly masked language modeling (MLM) which usually revolves around somehow masking parts a given sentence and asking the model with finding or reconstructing the initial sentence.
- Decoder-only Models:
Pre-training decoder models usually revolves around predicting the next word (token) in the sentence. During prediction it only accesses the words(tokens) positioned before in the sentence that’s why these types of models are also called auto-regressive models. Text Generation is one of the main tasks you can perform using decoders only models.
- Encoder-Decoder Models(Seq2seq):
Encoder-decoder models (sequence-to-sequence models) use both sections of the Transformer architecture. The attention layers of the encoder can access all the words in the given sentence, whereas the attention layers of the decoder can only access the words positioned before a given word in the input. Generally, encoder-decoder models are used for tasks like text-summarization, machine translation, question answering etc.
The pretraining of these models can be done using the objectives of encoder or decoder models, however a complex process also can be involved like T5 is pretrained by replacing random spans of text with a single mask and the objective is then to predict the masked text.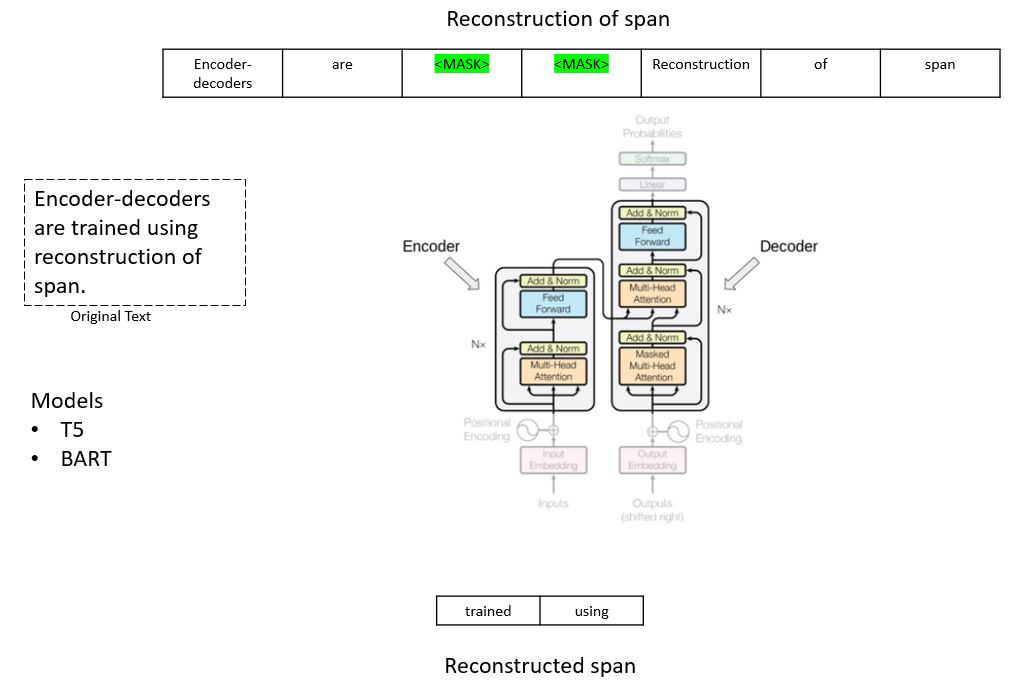
As we have gone through the basics of different types of LLMs in the next few posts we will go through how we can finetune or use these LLM models for different NLP tasks.
Stay tuned for more stuff on LLM.
Thanks for your time , do share in case you liked the content.