
In the previous article related to RNN , we understood the architecture of RNN , RNN has the problem working poorly when we need to maintain the long term dependencies (earlier layers of RNNs suffers the problem of vanishing gradients).
This problem has been almost solved with the new architecture of LSTMs (Long Short Term Memory) where the concepts of below given Gates has been introduced:
1. Learn Gate.
2. Forget Gate.
3. Remember Gate.
4. Use Gate.
Using all these gates we try to learn and forget from the short term and long term memory and we output new long and short term memory as shown below –
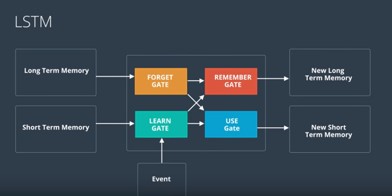
Now let’s go through each of these gates and the mathematical equations behind these gates.
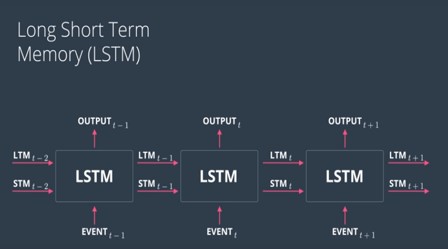
STM – Short Term Momory
LTM – Long Term Memory
Learn Gate:
Inputs – Short Term Memory & Event
Output – Nt * it
Step 1:
It combines the STM and the Event then multiples with a weight vector, adds the bias and squashes through a Tanh. This step generates new information from the STM and event. 
Step 2:
Ignores few parts this new information with multiplying the output of the below equation i.e. the ignore term. Sigmoid action squashes the value (i.e. the combination of STM & Event) between 0 & 1. One means keep the required information and Zero means ignore the unnecessary information.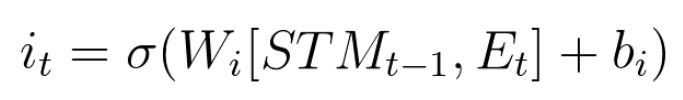
Final output of the Learn gate:
Forget Gate:
Input: LTM
Output: LTM * ft
Mainly works on the Long term memory and does the operation of what should we forget from the Long term memory using the short term memory information.
Step 1:
First the a forget factor is calculated as shown below , factor is being calculated from the previous short term memory and using the current event. Sigmoid action is again used to squash the value to 0 & 1. ![]()
Step 2:
Forget factor is then element wise multiplied with Long term memory to throw away few long term information as shown below – 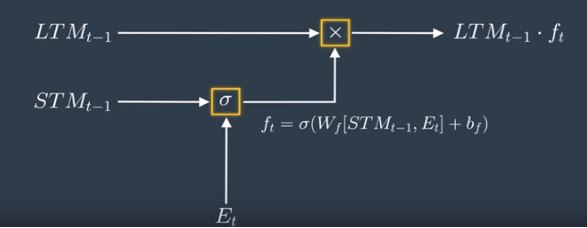
Remember Gate:
Inputs: Outputs of the Learn Gate and Forget Gate
Output: New Long Term Memory
Just adds the outputs of the Learn Gate and Forget Gate and produces the new long term memory as output , shown below (LTMt is the new long term memory)- 
Use Gate(output gate):
Inputs: Output of the forget gate , STM & Event
Output: New short term memory
Step 1:
Applies a Tanh at the output of the forget gate as shown below – 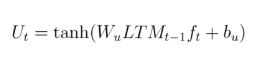
Step 2:
Applies a small neural network with sigmoid activation function on the short term memory and event as shown below – ![]()
Step 3:
Then the use gate does multiplication of the outputs of Step 1 & Step 2 and produces the output or the new Short Term Memory as shown below –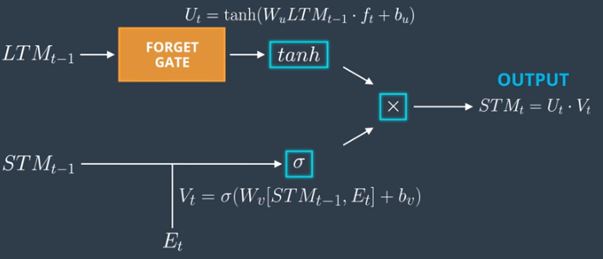
Putting it all together it looks like below –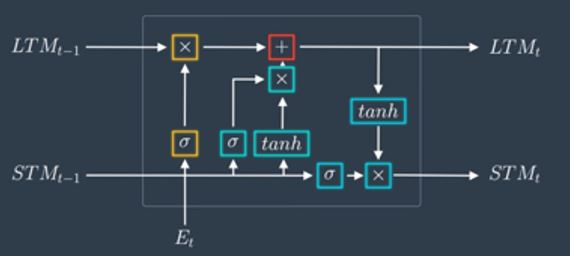
Image Credits: Udacity Deep Learning LSTM video tutorial created by Luis Serrano.
Do like , share and comment if you have any questions.