
In the last few posts, we talked about how to use Llama-2 model for performing different NLP tasks and for most of the cases I have used GPU in Kaggle kernels. Now there can be requirements to that you don’t have GPU and you need to build some apps using CPU only. In this short post we will see how we can use ctransformers library to load and do inference using LLama-2 in CPU only. ctransformers library are python bindings for the Transformer models implemented in C/C++ using GGML library. Run the below command to install ctransformer library.

ctransformer library essentially helps to load the quantized models into CPU. With the ever-increasing size of LLMs, quantization plays a crucial role to use these giant models in community hardware efficiently with minimum compromise in the model performance. Recently, 8-bit and 4-bit quantization has helped us of running LLMs on consumer hardware. GGML (created by Georgi Gerganov , hence the name) was designed to be used with the llama.cpp library. The library is written in C/C++ for efficient inference of Llama models. It can load GGML models and run them on a CPU. To get the llama-2 7B GGML models for different quantization to this hugging-face link – TheBloke/Llama-2-7B-Chat-GGML at main (huggingface.co)
Based on the choice of quantization you can download the corresponding model file and place it in a local folder as shown below –
As you can see, I have downloaded two different quantized models from the above given link 2bit and 4 bit quantized models.
They follow a particular naming convention: “q” + the number of bits used to store the weights (precision) + a particular variant. Here is a list of all the possible quant methods and their corresponding use cases, based on model cards made by TheBloke:
q2_k: Uses Q4_K for the attention.vw and feed_forward.w2 tensors, Q2_K for the other tensors.q3_k_l: Uses Q5_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else Q3_Kq3_k_m: Uses Q4_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else Q3_Kq3_k_s: Uses Q3_K for all tensorsq4_0: Original quant method, 4-bit.q4_1: Higher accuracy than q4_0 but not as high as q5_0. However has quicker inference than q5 models.q4_k_m: Uses Q6_K for half of the attention.wv and feed_forward.w2 tensors, else Q4_Kq4_k_s: Uses Q4_K for all tensorsq5_0: Higher accuracy, higher resource usage and slower inference.q5_1: Even higher accuracy, resource usage and slower inference.q5_k_m: Uses Q6_K for half of the attention.wv and feed_forward.w2 tensors, else Q5_Kq5_k_s: Uses Q5_K for all tensorsq6_k: Uses Q8_K for all tensorsq8_0: Almost indistinguishable from float16. High resource use and slow. Not recommended for most users.
Once you download and place the model in your local file system, now you can easily load the model using below shown process and see how fast the model loads from disk –
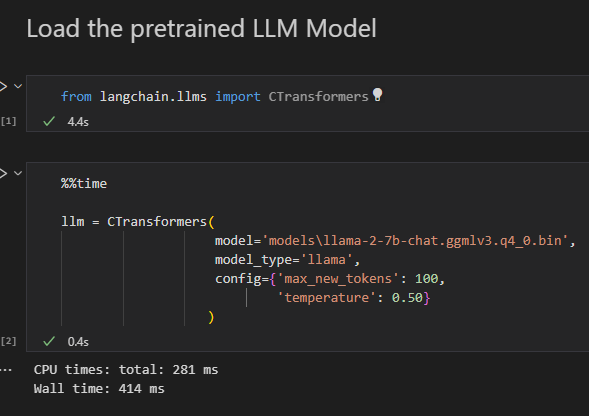
Once loaded 4 bit llama-2 quantized model takes around 3.53 GB disk space. Similar way you can also load 13B Llama-2 models in your CPU also for inference from this link. – https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/tree/main
Using the 4bit quantized Llama-2 model and Gradio I have created the below shown demo using CPU only.
Do let me know in the comments if you like the video or not and in case you want me to create YouTube videos along with blogposts in future. Thanks for reading.
Reference: Quantize Llama models with GGML and llama.cpp | Towards Data Science