
In the last post of this series , we got the basic ideas of Pytorch and how to use few of the features of the Pytorch. In this tutorial we will go through how to code a deep neural network. First we will go through, what are the basic steps required in neural network and then we will see how to implement the same in Pytorch fashion and taking advantage of PyTorch’s nn classes to make the code more concise and flexible.
First , lets go through what are steps are required in Neural Network Implementation –
- Initialize weights
- Do forward propagation
- Calculate loss
- Calculate derivatives (backward propagation)
- Update the weights (backward propagation)
- Keep on doing previous steps until you reach global minimum through Gradient Descent.
In the previous tutorial he have seen that Pytorch has the in built Auto-grad function to calculate gradients. Let’s see how using this autograd features we can code a simple one layer neural network from scratch in the below shown way.
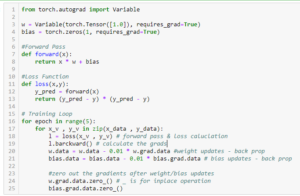
Now let’s do this using Pytorch in built functionalities –
Do like , share and comment if you have any questions.